Pika 与 Codis
背景
面对kv类型数据在公司的存储量越来越大,以及在性能响应不敏感的情况下,利用原生的codis方案来存储数据的方案,成本也越来越高,在这种场景下,急需一种替代方案能够有效兼顾成本与性能。故引入了pika来作为codis的底层存储,来替换成本较高的codis-server,并围绕pika的方案进行了一系列的设计改造。
codis的原理设计
codis项目主要分为codis-fe、codis-dashboard、codis-proxy和codis-server这四个组件。
codis-fe主要是方便统一管理多套的codis-dasbhoard,并提供运维友好的管理界面,在运维性与管理性上面都比较友好。
codis-dashboard主要就是完成有关slot、codis-proxy和zk(或者etcd)等组件的数据一致性,整个集群的运维的状态,数据的扩容缩容和组件高可用的管理,类似于k8s的api-server的功能。
codis-proxy主要就是提供给业务层面使用的访问代理,解析请求路由并将key的路由信息路由到对应的后端group上面,而且还有一个很重要的功能就是当通过codis-fe来进行集群的扩缩容的时候,codis-proxy会根据group的迁移状态,来触发key的检查或者迁移的功能从而完成在不中断业务服务的情况下热迁移数据,从而保证业务的可用性。
codis的运行原理
codis在运行的过程中与官网给定的原理图是一致的。
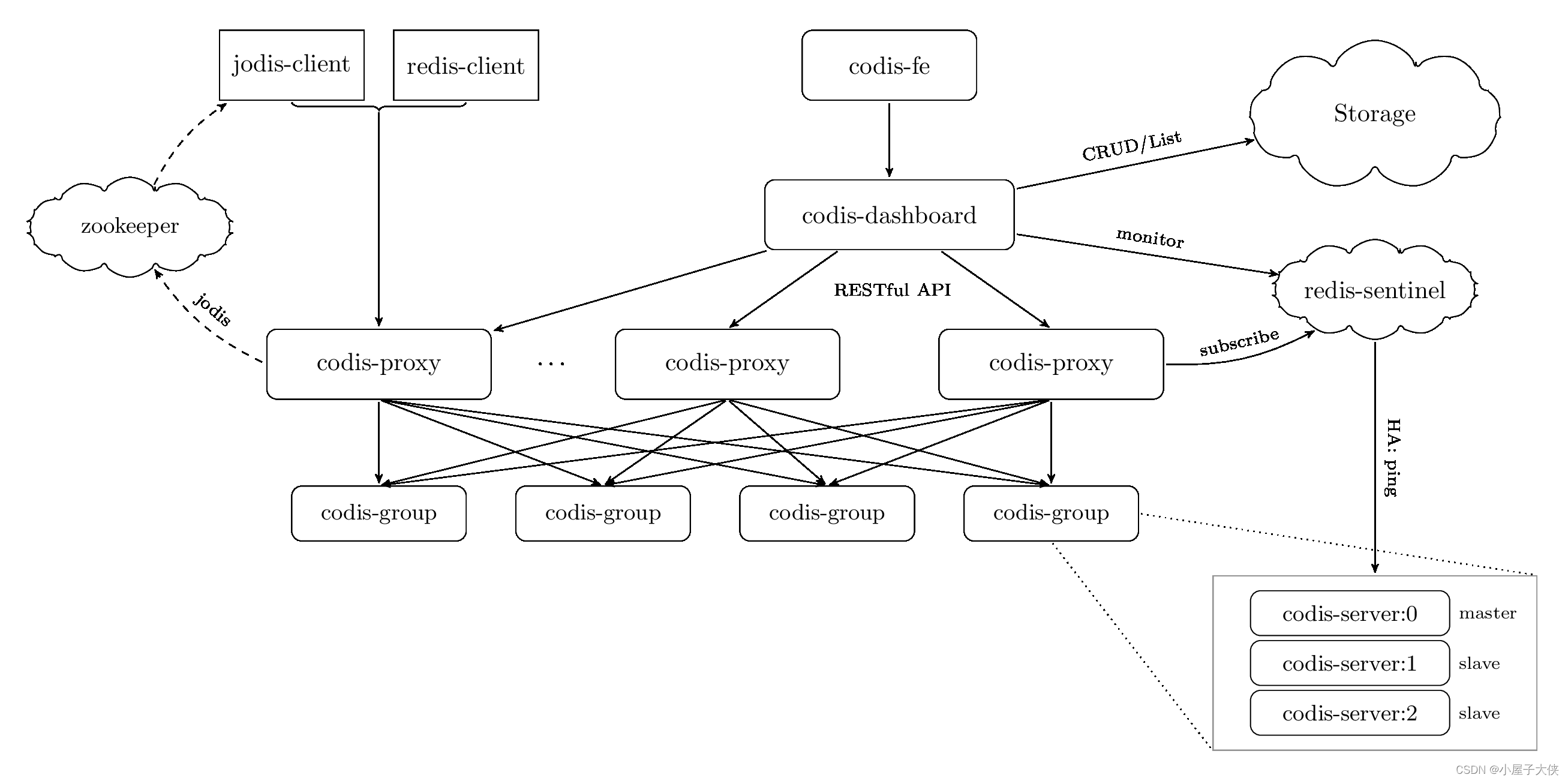
通过zk的路径暴露,来进行codis-proxy的负载均衡和服务发现,可使用官方提供的jodis或者自己实现的redis-client来进行封装。
codis-dashboard通过接受codis-fe的扩缩容、上下线,集群主从状态等管理指令。在接受到指令之后,通过将状态的存储并将状态推送到codis-proxy,从而使在codis-fe上线的管理能够动态的在codis-proxy的数据能够动态路由,所有的集群状态的管理都会通过codis-dashboard来保持一致。
codis的扩缩容原理
通过对codis整个的运行图的简单的概述,我们来进一步探讨一下有关codis是如何进行一个动态的扩缩容的。
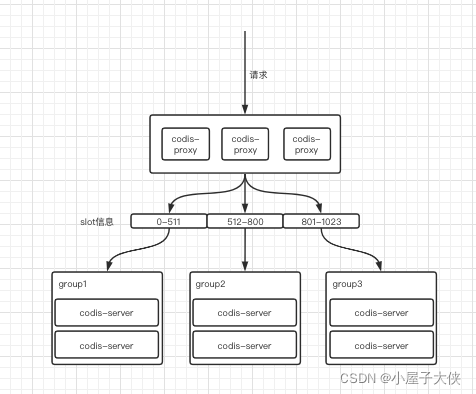
以扩展group为例,整个的集群流程如下。
原始集群如下,此时需要将group4加入集群,并将group3的901-1023的slot迁移到group4。
迁移完成之后的状态如下。
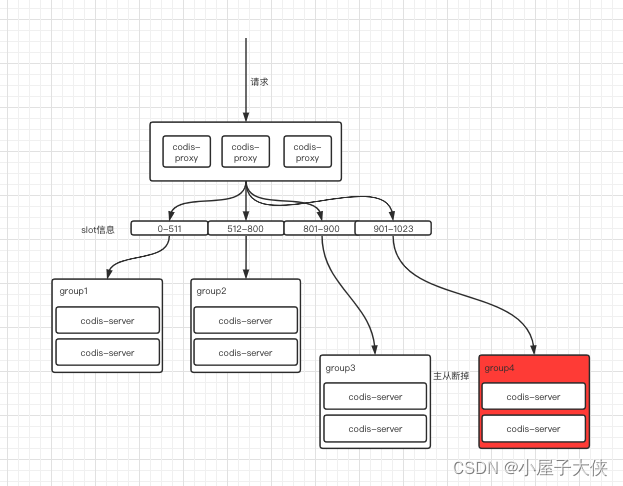
此时group4就新加入到codis集群中,并运行的数据slot为原group3的901-1023的slot。
详细的迁移步骤可以分为如下几步。
codis-fe将状态发往codis-dashboard
在codis-fe上面,在Migrate Range上面将slot填写为901-1023,迁移至group4。
此时codis-fe就会往codis-dashboard发送一个包含/api/topom/slots/action/create-range/…/901/1023/1的uri,此时codis-dashboard就会执行如下的操作。
func (s *Topom) SlotCreateActionSome(groupFrom, groupTo int, numSlots int) error {
s.mu.Lock()
defer s.mu.Unlock()
ctx, err := s.newContext()
if err != nil {
return err
}
g, err := ctx.getGroup(groupTo)
if err != nil {
return err
}
if len(g.Servers) == 0 {
return errors.Errorf("group-[%d] is empty", g.Id)
}
var pending []int
for _, m := range ctx.slots { // 验证slot的状态
if len(pending) >= numSlots {
break
}
if m.Action.State != models.ActionNothing {
continue
}
if m.GroupId != groupFrom {
continue
}
if m.GroupId == g.Id {
continue
}
pending = append(pending, m.Id)
}
for _, sid := range pending {
m, err := ctx.getSlotMapping(sid)
if err != nil {
return err
}
defer s.dirtySlotsCache(m.Id) // 将该slot标记为需要重新写入zk或者etcd来维持状态
m.Action.State = models.ActionPending
m.Action.Index = ctx.maxSlotActionIndex() + 1
m.Action.TargetId = g.Id
if err := s.storeUpdateSlotMapping(m); err != nil { // 更新该slot的状态,该结构维护了group到slot的对应的关系,用于在codis-proxy中就行每个slot的路由代理
return err
}
}
return nil
}
从流程可知,创建迁移过程之后,其实就是将迁移的信息写入zk或者etcd中来保存迁移的状态,并且通过codis-dashboard自己启动的状态机来进行每一步的状态迁移。
codis-dashboard接受状态并开始启动迁移
在codis-fe成功写入迁移信息到zk或者etcd之后,此时就通过codis-dashboard自身监控服务迁移的状态来启动数据迁移。
//处理slot操作
go func() {
for !s.IsClosed() {
if s.IsOnline() {
if err := s.ProcessSlotAction(); err != nil {
log.WarnErrorf(err, "process slot action failed")
time.Sleep(time.Second * 5)
}
}
time.Sleep(time.Second)
}
}()
该协程就会一直刷新查看是否有迁移的状态,如果有迁移的状态就会进行处理。有关对该状态处理的核心函数如下。
func (s *Topom) SlotActionPrepareFilter(accept, update func(m *models.SlotMapping) bool) (int, bool, error) {
s.mu.Lock()
defer s.mu.Unlock()
// 上下文
ctx, err := s.newContext()
if err != nil {
return 0, false, err
}
// 取最小的action index
var minActionIndex = func(filter func(m *models.SlotMapping) bool) (picked *models.SlotMapping) {
for _, m := range ctx.slots {
// 遍历所有的slotMapping, 如果 m.Action.State == "", 跳出本次循环, 执行下次循环
if m.Action.State == models.ActionNothing {
continue
}
// 将slotMapping传入filter函数中, 如果m.Action.State != models.ActionPending, 才执行if里面的语句
if filter(m) {
if picked != nil && picked.Action.Index < m.Action.Index {
continue
}
//只有一个slot没有执行过update方法,accept才会返回true;也就是说,一个slot只会被处理一次
// marks里面保存的是:已经分配了group,或者即将分配group,这2种group id
// 如果m的即将分配group id在marks里面, accept(m)就返回false, 这样就保证了同时只有一个slot迁入到同一个group下, 在一个redis下面,同时只有一个slot被迁移��出去
if accept == nil || accept(m) {
picked = m
}
}
}
return picked
}
// 第一种情况是: 取正在做slot迁移的slot里面action.id最小的那个slot
// 第二中情况是: 上面的没有取到的前提下,才做第二种操作,取出pending状态的slot里面action.id最小的那个slot
var m = func() *models.SlotMapping {
// 取出 m.Action.State != "" and m.Action.State != pending 的slot里面action.id最小的那个slot
// 即: 取出正在做slot迁移的slot里面action.id最小的那个slot
// 赋值给picked
// 然后返回
var picked = minActionIndex(func(m *models.SlotMapping) bool {
return m.Action.State != models.ActionPending
})
if picked != nil {
return picked
}
// 如果上面没有取到,执行下面的语句
if s.action.disabled.IsTrue() {
return nil
}
// 取出 m.Action.State != "" and m.Action.State == models.ActionPending的slot里面action.id最小的那个slot
// 即: 取出pending状态的slot里面action.id最小的那个slot
// 赋值给picked
// 然后返回
return minActionIndex(func(m *models.SlotMapping) bool {
return m.Action.State == models.ActionPending
})
}()
// 上面2种情况都没有取到值的话,说明不需要做slot迁移, 因为没有取到正在做slot迁移的最小的action.id, 也没有取到准备做slot迁移的最小的action.id
if m == nil {
return 0, false, nil
}
if update != nil && !update(m) {
return 0, false, nil
}
log.Warnf("slot-[%d] action prepare:\n%s", m.Id, m.Encode())
//变更每个SlotMapping的action.state,并与zk交互
//另外,Action.state符合preparing或者prepared的时候,要将SlotMapping同步到proxy
switch m.Action.State {
case models.ActionPending:
defer s.dirtySlotsCache(m.Id)
// 将action state状态改成 preparing
m.Action.State = models.ActionPreparing
// 写入zk中
if err := s.storeUpdateSlotMapping(m); err != nil {
return 0, false, err
}
// 无条件继续执行下面case中语句
fallthrough
case models.ActionPreparing:
defer s.dirtySlotsCache(m.Id)
log.Warnf("slot-[%d] resync to prepared", m.Id)
// 将action state状态改成 ActionPrepared
m.Action.State = models.ActionPrepared
// 将slotMapping信息刷新到proxy中, 如果刷失败了, 将m.Action.State改回ActionPreparing, 返回
if err := s.resyncSlotMappings(ctx, m); err != nil {
log.Warnf("slot-[%d] resync-rollback to preparing", m.Id)
// slotMapping信息刷新到proxy失败, m.Action.State改回ActionPreparing
m.Action.State = models.ActionPreparing
s.resyncSlotMappings(ctx, m)
log.Warnf("slot-[%d] resync-rollback to preparing, done", m.Id)
return 0, false, err
}
// 刷新proxy信息成功后, 将m.Action.State = models.ActionPrepared写入到zk中
if err := s.storeUpdateSlotMapping(m); err != nil {
return 0, false, err
}
// 无条件继续执行下面case中语句
fallthrough
case models.ActionPrepared:
defer s.dirtySlotsCache(m.Id)
log.Warnf("slot-[%d] resync to migrating", m.Id)
// 将action state状态改成 ActionMigrating
m.Action.State = models.ActionMigrating
// 将slotMapping信息刷新到proxy中, 如果刷失败了, 返回
if err := s.resyncSlotMappings(ctx, m); err != nil {
log.Warnf("slot-[%d] resync to migrating failed", m.Id)
return 0, false, err
}
// 刷成功后, 将m.Action.State = models.ActionMigrating 写入zk
if err := s.storeUpdateSlotMapping(m); err != nil {
return 0, false, err
}
// 无条件继续执行下面case中语句
fallthrough
case models.ActionMigrating:
return m.Id, true, nil
case models.ActionFinished:
return m.Id, true, nil
default:
return 0, false, errors.Errorf("slot-[%d] action state is invalid", m.Id)
}
}
在ActionPreparing的状态的时候,就会将数据写入zk或者etcd从而通知到了codis-proxy状态更新。
在codis-dashboard中就会通过processSlotAction函数来进行后端数据的迁移,其中最核心的函数为newSlotActionExecutor。
// 调用redis的SLOTSMGRTTAGSLOT命令, 进行redis slot 迁移
func (s *Topom) newSlotActionExecutor(sid int) (func(db int) (remains int, nextdb int, err error), error) {
s.mu.Lock()
defer s.mu.Unlock()
// 上下文
ctx, err := s.newContext()
if err != nil {
return nil, err
}
//根据slot的id获取SlotMapping,主要方法就是return ctx.slots[sid], nil
m, err := ctx.getSlotMapping(sid)
if err != nil {
return nil, err
}
switch m.Action.State {
//最初slot还处在迁移过程中,即migrating
case models.ActionMigrating:
if s.action.disabled.IsTrue() {
return nil, nil
}
// m.groupId 主从在切换时, 不做slot迁移操作
if ctx.isGroupPromoting(m.GroupId) {
return nil, nil
}
// m.action.targetId 主从在切换时, 不做slot迁移操作
if ctx.isGroupPromoting(m.Action.TargetId) {
return nil, nil
}
//迁移过程中,一个slot本身所在的group以及目标group的Promoting.State都必须为空才可以做迁移
from := ctx.getGroupMaster(m.GroupId)
//取出group 2的第一个server,也是master
dest := ctx.getGroupMaster(m.Action.TargetId)
//Topom的action中的计数器加一
s.action.executor.Incr()
return func(db int) (int, int, error) {
//每执行一个槽的迁移操作,Topom的action中的计数器就减1
defer s.action.executor.Decr()
if from == "" {
return 0, -1, nil
}
//从cache中得到group 1的redisClient,这个client由addr, auth, timeout,Database,redigo.Conn组成: 如果cache没有, 就新建
c, err := s.action.redisp.GetClient(from)
if err != nil {
return 0, -1, err
}
//将刚才新建的或者从cache中取出的redis client再put到Topom.action.redisp中
defer s.action.redisp.PutClient(c)
//这里db是0,相当于redis从16个库中选择0号
if err := c.Select(db); err != nil {
return 0, -1, err
}
var do func() (int, error)
method, _ := models.ParseForwardMethod(s.config.MigrationMethod)
switch method {
case models.ForwardSync:
do = func() (int, error) {
//调用redis的SLOTSMGRTTAGSLOT命令,随机选择当前slot的一个key,并将与这个key的tag相同的k-v全部迁移到目标机
return c.MigrateSlot(sid, dest)
}
case models.ForwardSemiAsync:
var option = &redis.MigrateSlotAsyncOption{
MaxBulks: s.config.MigrationAsyncMaxBulks,
MaxBytes: s.config.MigrationAsyncMaxBytes.AsInt(),
NumKeys: s.config.MigrationAsyncNumKeys,
Timeout: math2.MinDuration(time.Second*5,
s.config.MigrationTimeout.Duration()),
}
//调用redis的SLOTSMGRTTAGSLOT-ASYNC命令,参数是target redis的ip和port
do = func() (int, error) {
return c.MigrateSlotAsync(sid, dest, option)
}
default:
log.Panicf("unknown forward method %d", int(method))
}
n, err := do()
if err != nil {
return 0, -1, err
} else if n != 0 {
return n, db, nil
}
nextdb := -1
//通过info命令查keyspace信息并做处理,这里取出的m为空
m, err := c.InfoKeySpace()
if err != nil {
return 0, -1, err
}
for i := range m {
if (nextdb == -1 || i < nextdb) && db < i {
nextdb = i
}
}
return 0, nextdb, nil
}, nil
case models.ActionFinished:
return func(int) (int, int, error) {
return 0, -1, nil
}, nil
default:
return nil, errors.Errorf("slot-[%d] action state is invalid", m.Id)
}
}
通过调用需要迁移数据的codis-server来主动进行数据的同步信息。
如果在数据同步中,通过codis-proxy来访问数据,codis-proxy则根据配置文件要么去查找一下新节点数据是否存在,如果不存在则将数据迁移至新节点上面来从而保持数据的一致性。
codis-dashboard完成
当所有的slot迁移完成之后,就会在zk或者etcd中更新当前的slot状态,从而完成整个迁移过程。
整个迁��移流程可简单如下所示。
pika简介
pika是360团队开源而来的一个兼容redis协议底层选用rocksdb的一个kv存储,该项目加入了开放原子开源基金会,并且在主流版本上面提供codis的接入能力。故考虑通过引入pika来替换codis中的codis-server组件。
pika既支持单节点模式也支持分布式模式,即每个slot都可以通过单独的管理迁移。在业务实践中考虑到数据量相对较大,故在最开始的时候就是使用的分布式模式,在后续的设计改造中也是依据该模式进行。
pika接入codis的挑战
pika官方支持的codis-server的命令
通过查阅pika的源码(3.4.0版本),在位于pika_command.h头文件中找到如下。
//Codis Slots
const std::string kCmdNameSlotsInfo = "slotsinfo";
const std::string kCmdNameSlotsHashKey = "slotshashkey";
const std::string kCmdNameSlotsMgrtTagSlotAsync = "slotsmgrttagslot-async";
const std::string kCmdNameSlotsMgrtSlotAsync = "slotsmgrtslot-async";
const std::string kCmdNameSlotsDel = "slotsdel";
const std::string kCmdNameSlotsScan = "slotsscan";
const std::string kCmdNameSlotsMgrtExecWrapper = "slotsmgrt-exec-wrapper";
const std::string kCmdNameSlotsMgrtAsyncStatus = "slotsmgrt-async-status";
const std::string kCmdNameSlotsMgrtAsyncCancel = "slotsmgrt-async-cancel";
const std::string kCmdNameSlotsMgrtSlot = "slotsmgrtslot";
const std::string kCmdNameSlotsMgrtTagSlot = "slotsmgrttagslot";
const std::string kCmdNameSlotsMgrtOne = "slotsmgrtone";
const std::string kCmdNameSlotsMgrtTagOne = "slotsmgrttagone";
对比查看一下codis-server支持的命令如下。
{"slotsinfo",slotsinfoCommand,-1,"rF",0,NULL,0,0,0,0,0},
{"slotsscan",slotsscanCommand,-3,"rR",0,NULL,0,0,0,0,0},
{"slotsdel",slotsdelCommand,-2,"w",0,NULL,1,-1,1,0,0},
{"slotsmgrtslot",slotsmgrtslotCommand,5,"w",0,NULL,0,0,0,0,0},
{"slotsmgrttagslot",slotsmgrttagslotCommand,5,"w",0,NULL,0,0,0,0,0},
{"slotsmgrtone",slotsmgrtoneCommand,5,"w",0,NULL,0,0,0,0,0},
{"slotsmgrttagone",slotsmgrttagoneCommand,5,"w",0,NULL,0,0,0,0,0},
{"slotshashkey",slotshashkeyCommand,-1,"rF",0,NULL,0,0,0,0,0},
{"slotscheck",slotscheckCommand,0,"r",0,NULL,0,0,0,0,0},
{"slotsrestore",slotsrestoreCommand,-4,"wm",0,NULL,0,0,0,0,0},
{"slotsmgrtslot-async",slotsmgrtSlotAsyncCommand,8,"ws",0,NULL,0,0,0,0,0},
{"slotsmgrttagslot-async",slotsmgrtTagSlotAsyncCommand,8,"ws",0,NULL,0,0,0,0,0},
{"slotsmgrtone-async",slotsmgrtOneAsyncCommand,-7,"ws",0,NULL,0,0,0,0,0},
{"slotsmgrttagone-async",slotsmgrtTagOneAsyncCommand,-7,"ws",0,NULL,0,0,0,0,0},
{"slotsmgrtone-async-dump",slotsmgrtOneAsyncDumpCommand,-4,"rm",0,NULL,0,0,0,0,0},
{"slotsmgrttagone-async-dump",slotsmgrtTagOneAsyncDumpCommand,-4,"rm",0,NULL,0,0,0,0,0},
{"slotsmgrt-async-fence",slotsmgrtAsyncFenceCommand,0,"rs",0,NULL,0,0,0,0,0},
{"slotsmgrt-async-cancel",slotsmgrtAsyncCancelCommand,0,"F",0,NULL,0,0,0,0,0},
{"slotsmgrt-async-status",slotsmgrtAsyncStatusCommand,0,"F",0,NULL,0,0,0,0,0},
{"slotsmgrt-exec-wrapper",slotsmgrtExecWrapperCommand,-3,"wm",0,NULL,0,0,0,0,0},
{"slotsrestore-async",slotsrestoreAsyncCommand,-2,"wm",0,NULL,0,0,0,0,0},
{"slotsrestore-async-auth",slotsrestoreAsyncAuthCommand,2,"sltF",0,NULL,0,0,0,0,0},
{"slotsrestore-async-select",slotsrestoreAsyncSelectCommand,2,"lF",0,NULL,0,0,0,0,0},
{"slotsrestore-async-ack",slotsrestoreAsyncAckCommand,3,"w",0,NULL,0,0,0,0,0},
��对比而言发现pika实现的命令相对较少,那具体接入codis中能否正常使用还有待观察,并且在codis-server和pika支持的语法上面来讲当前就已经有所不同。
在pika的集群模式下面需要输入如下指令。
redis-cli -p 9221 pkcluster slot info 1
这也意味着,在命令调度与管理层也必须加上对于pika的语法格式的支持。
在前期的调研阶段得益于研发同学的大力支持,在codis-dashboard层中,通过修改部分源码逻辑来支持有关pika的主从同步、主从提升等命令,从而完成了在codis-fe层面的操作。
在完成了如上的操作之后,继续进行数据迁移的时候,发现在codis-fe界面上面都显示迁移完成,但是数据却并没有迁移,导致新迁移的数据其实并没有迁移对对应的集群上面去。具体为什么会出现如下的问题呢?在codis-fe界面上面也没有明显的报错信息,问题出在了哪里呢?
此时继�续查看一下pika的有关slot的源码。
void SlotsMgrtSlotAsyncCmd::Do(std::shared_ptr<Partition> partition) {
int64_t moved = 0;
int64_t remained = 0;
res_.AppendArrayLen(2);
res_.AppendInteger(moved);
res_.AppendInteger(remained);
}
从源码查看发现,我们日常运行的情况下,通过codis-dashboard发送给pika的指令直接就是成功返回,从而使codis-dashboard在迁移的时候就立马就收到了成功的信号,从而直��接就修改了迁移的状态到成功,但是其实数据迁移并没有执行。
针对这种情况,我们查阅了有关pika的官方文档 Pika配合Codis扩容案例。
从官方的文档来看,这种迁移的方案是一种有损可能会丢数据的方案,在这种情况下需要依靠自己来调整迁移的方案。
pika迁移工具的设计
迁移工具的整体流程如下:
原始集群信息如下

此时需要迁移901-1023个slot信息迁移到新组件上面即group4作为新实例提供服务。
首先开发一个pika的迁移工具,该工具可以转发代理codis的请求。先将801-1023的信息迁移到pika的迁移工具。

此时pika迁移工具就将801-900的写信息写入group3,将901-1023的写信息写入group4,然后如果查数据先查group4,如果没有则查group3。
此时pika迁移工具接入完成之后,转发代理到后端服务。接入完成之后再进行主从同步信息,将group3同�步到group4。

将slot901-1023的数据从group3迁移到group4上面之后,因为没有新的group3的901-1023的数据写入,故可以放心的等待数据迁移完成。
迁移完成之后就断开主从,再将pika的迁移工具的slot信息,即801-900迁移回group3,将901-1023迁移回group4,此时数据迁移完成。

至此,pika通过迁移工具完成对集群的扩容,该工具大部分工具跟codis-proxy的大部分功能相似,只不过需要将对应的路由规则进行转换并添加上对于pika的语法指令就可以了。
总结
本文仅仅是针对pika在codis场景下的一些思考和探索。由于本人才疏学浅,如有错误请批评指正。